
Logical Data Management for mere mortals
The story I wasn't ready to tell two years ago. AI changed that...


Two years ago, I was approached by a publisher to write a short book (~100 pages) about Logical Data Management.
I did not write it.
Not because the topic was weak (quite the opposite). The topic was strong, maybe even stronger than I fully realized at the time. But I had this strange feeling that the story was not ready yet. It sounded like an architecture topic. Useful, yes. Important, hell, yes. But still one (or two) step away from the pain that real people feel every Monday morning when someone asks them for “just a simple number”.
And, of course, that number is never simple.
“Can you give me revenue by customer segment for last quarter?”
Sounds like a piece of cake, right?.
Then you open the first report and realize that “customer segment” means one thing in CRM, another thing in the data warehouse, something completely different in the finance model, and absolutely nothing in the Excel file that the sales team has been updating manually since 2019.
Welcome to modern data management.
Everything is centralized.
Everyone is still waiting.
We solved the movement problem
For the last 20 years, a huge part of data management was about movement.
Move data from operational systems into a data warehouse. Move it from the warehouse into marts. Move it from files into tables. Move it from on-premises into the cloud. Move it from a lake into a lakehouse. Move it from one platform into another platform because the previous platform promised to solve everything, but apparently everything needed a new SKU.
I am exaggerating a bit.
Only a bit.
The logic was easy to understand. Data was scattered across systems, and scattered data is painful. If sales data lives in CRM, product data lives in ERP, finance data lives in another system, and web analytics lives somewhere else, then the business cannot ask questions across those systems without a lot of glue.
So, we built the glue.
ETL pipelines. ELT pipelines. Data warehouses. Data lakes. Lakehouses. Medallion design pattern. Data marts. Semantic models. Cubes, if you have a few gray hairs (or no hair at all) like me.
The industry became very good at moving data.
And that solved many problems. I do not want to pretend otherwise. Centralized analytical platforms brought consistency, scale, performance, governance, and a much better foundation for reporting. Without them, many organizations would still be living in spreadsheet archaeology.
But moving data into one place did not automatically make it usable.
That is the part we did not always say loudly enough.
The report is fast. The answer is slow.
There is a funny thing that happens in many data projects.
The technical team celebrates that the warehouse query now runs in 4 seconds instead of 40 minutes. And they should celebrate! That is real progress.
Then the business user says: “Great. But is this number correct?”
Silence.
Because the query may be fast, but trust is not fast. Meaning is not fast. Ownership is not fast. Security approval is not fast. The conversation about whether canceled orders should be included in net revenue is definitely not fast.
This is the less obvious truth: the speed of the database is only one part of the speed of analytics.
If the report runs in 4 seconds, but it takes 4 days to understand which table to use, which column is certified, whether the definition changed last month, and who owns the metric, then the business is not experiencing self-service.
It is experiencing a faster waiting room.

Self-service became self-navigation
I have always liked the idea of self-service analytics. Power BI, semantic models, dataflows, Fabric, Databricks, Snowflake, all of it. Give people the tools. Give them governed data. Let them answer more questions without opening a ticket every time.
Beautiful idea.
But in many organizations, self-service became something else: self-navigation.
This is the data lake. Good luck.
Here are 600 tables. Good luck.
Here are 80 semantic models, 17 of which contain a measure called Revenue. Good luck.
Here is the certified dataset, but the person who built it left the company last year. Good luck.
But, you might say: “Nikola, this is not a technology problem. This is a governance problem.”
Yes…
…And no.
It is a governance problem. It is also an architecture problem. It is also a product problem. It is also a language problem.
The business does not think in tables, pipelines, partitions, notebooks, and bronze-silver-gold layers. The business thinks in customers, orders, invoices, churn, margin, inventory, risk, claims, campaigns, and targets.
If our data platform exposes only technical objects, we should not be surprised when business users keep asking technical people to translate.
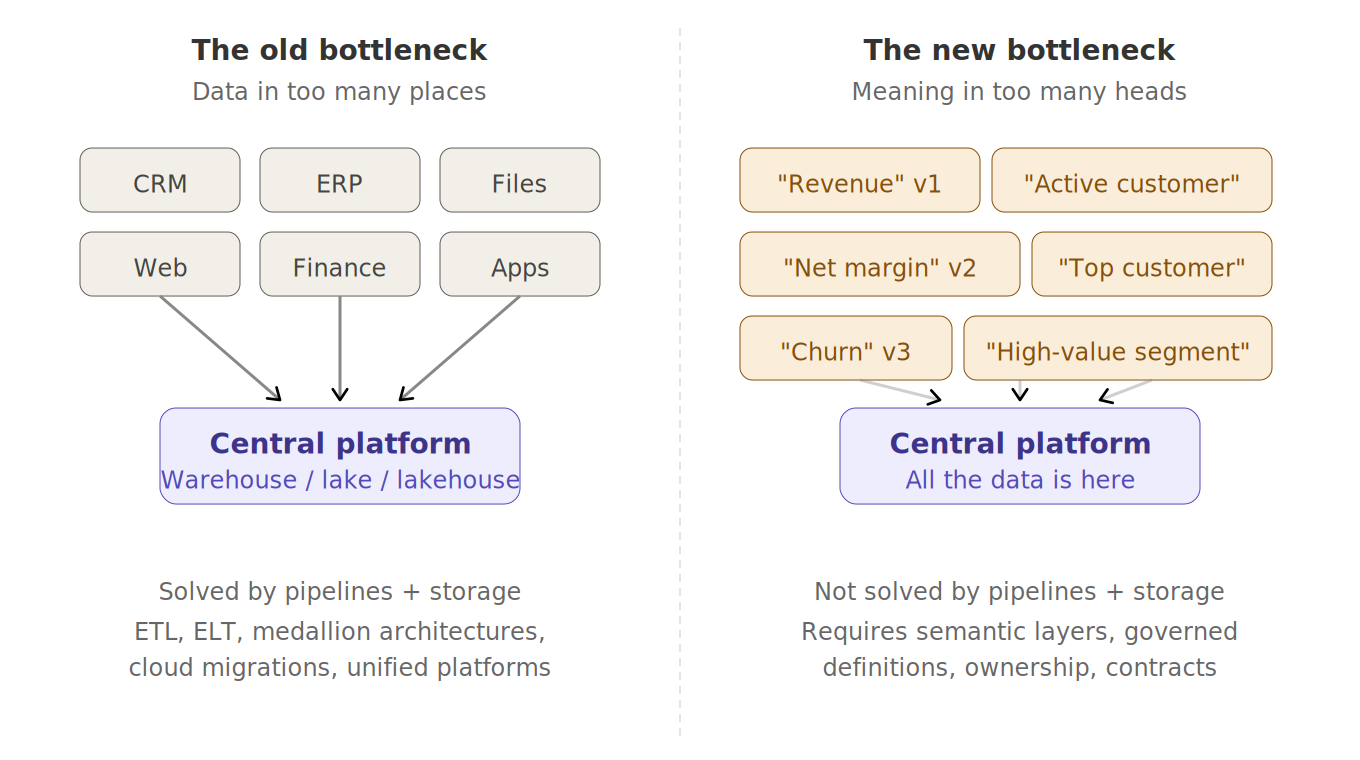
Centralization created a new bottleneck
Traditional data architecture had an obvious bottleneck: data lived in too many places.
Centralization attacked that bottleneck. Good.
Then a new bottleneck appeared.
The meaning of data lived in too many heads.
This is the part that makes logical data management interesting to me. And, it’s not because it is another architecture label. We have enough labels to wallpaper a small apartment. It is interesting because it asks a better question:
How do we manage the logic around data, not only the data itself?
That logic includes definitions, relationships, business rules, security policies, ownership, lineage, quality signals, delivery patterns, and the semantic layer that allows humans to ask questions without memorizing physical storage.
In plain English: if the data platform is the kitchen, logical data management is the menu, the recipe book, the allergy warnings, and the person who knows that “the usual” means black coffee with no sugar.
The ingredients matter.
But nobody wants to eat ingredients.
