
Same lake, different shores: Warehouse vs. Lakehouse in 2026
If I had a euro for every time someone asked me "should I use the Warehouse or the Lakehouse?" - I'd have enough to fund a month of exclusive vacation...


If I had a euro for every time someone asked me “should I use the Warehouse or the Lakehouse in Microsoft Fabric?” - I’d have enough to fund an F64 for a month:) And, my answer has been the same for a while now: you’re asking the wrong question.
Let me explain why - even if you were asking the right question a year ago, the answer has changed. Three things happened in the last 12 months that fundamentally shifted the calculus: materialized lake views went GA at FabCon Atlanta in March 2026, SQL databases in Fabric went GA, and the Warehouse got many limitations lifted in the meantime.
The old framing - “Lakehouse for data engineering, Warehouse for BI” - doesn’t hold anymore. In 2026, the question isn’t which one. It’s which combination, and where does each layer sit.
Let me walk you through what changed and what I’m doing differently in client engagements because of it.
The ground truth: same lake, same engine
Before we get into the shifts, let me make sure we’re on the same page about what these things actually share, because this is the most important fact and the most underappreciated one.
Both the Warehouse and the Lakehouse store data as Delta tables in OneLake. Same storage, same format, same lake. When you create a table in a Lakehouse and then query it from a Warehouse using a three-part name, no data moves. You’re reading the same Delta files from the same OneLake location.
And, both use the same SQL engine under the hood - the Polaris engine. The SQL analytics endpoint that Fabric auto-generates for every Lakehouse? That IS the Warehouse engine, just in read-only mode. So the compute is the same too.
If storage is the same and the SQL engine is the same… What’s actually different?
The write model and the transformation interface. That’s it. That’s the real fork in the road.
The Warehouse gives you full T-SQL DML: INSERT, UPDATE, DELETE, MERGE, stored procedures, views, functions - the complete toolbox that SQL Server developers have used for decades. You write data with T-SQL. You transform data with T-SQL. You serve data with T-SQL.
The Lakehouse SQL endpoint is read-only. If you want to write data to a Lakehouse, you go through Spark - PySpark notebooks, Spark SQL, Scala, or R. The Lakehouse is a Spark-first environment that happens to expose a SQL endpoint for querying.
Ok, so far so familiar. But, bear with me, now it gets interesting, because three things happened in the last year that blurred these boundaries in ways most comparison articles haven’t caught up with yet.
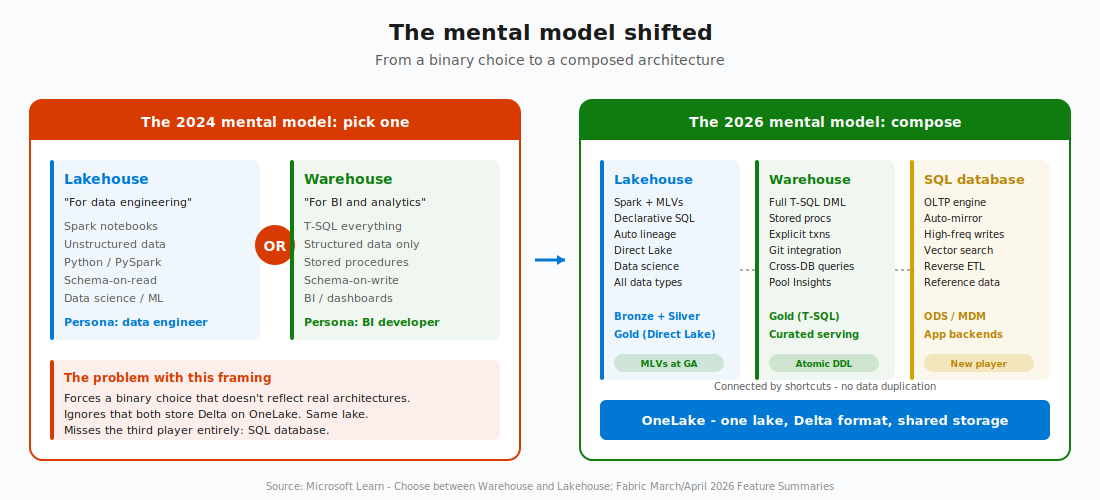
What changed: three shifts that broke the old framing
Shift 1: MLVs gave the Lakehouse a transformation layer
Before materialized lake views, the Lakehouse’s transformation story was: write notebooks, build pipelines to orchestrate them, configure schedules, add custom data quality logic, and wire up monitoring. Five different surfaces, five different things to debug when something broke.
The Warehouse, meanwhile, had stored procedures, views, and T-SQL - a mature, self-contained transformation story that SQL developers already knew.
That gap was real, and it was the single strongest argument for choosing the Warehouse: “use the Warehouse because it has a proper transformation layer.”
Then MLVs went GA at FabCon Atlanta. I already wrote about MLVs in my previous article. Now? The Lakehouse has declarative SQL transformations with automatic lineage inference, optimal refresh (skip / incremental / full), built-in data quality constraints, and multi-schedule support. You can build a full medallion pipeline ( bronze to silver to gold) without writing a single notebook. Just SQL statements.
The implication is significant: the Lakehouse’s transformation story isn’t better or worse than the Warehouse’s anymore - it’s just different. MLVs are declarative and dependency-aware. The engine figures out the execution order from your SQL. T-SQL stored procedures are procedural and manually orchestrated. You tell the engine what to do and in what order. Different tools for different thinking styles.
I wrote a full deep dive on MLVs recently - if you haven’t read it, start there. It covers the syntax, optimal refresh internals, the five GA changes, and the limitations you need to know.
Can it get better than this? Actually, yes.
Shift 2: SQL databases brought OLTP into Fabric
Before SQL databases in Fabric, the platform was analytics-only. If you needed an operational data store, a reference data hub, or a transactional backend for a Power App, you went to Azure SQL Database outside Fabric. Your OLTP and OLAP worlds lived on separate planets. You built pipelines to move data between them.
If you want to learn more about SQL database in Fabric, I have you covered in this article.
Then Fabric databases went GA in late 2025. SQL database in Fabric is essentially a SaaS Azure SQL DB that lives inside Fabric, backed by the same SQL Server engine that’s been trusted for 30+ years. But, with one crucial enhancement: it automatically mirrors its data to OneLake as Delta, making it instantly available for analytics across Fabric, without you building a single pipeline.
I covered this in detail on my blog, but the short version is: the old two-player game (Warehouse vs. Lakehouse) is now a three-player game. SQL database handles the use cases that neither Warehouse nor Lakehouse was designed for: high-frequency writes, OLTP workloads, reference data management, operational data stores, and even reverse ETL scenarios where curated analytics data gets pushed back into operational systems.
I hear you, I hear you: Nikola, isn’t it confusing to have yet ANOTHER data store in Fabric? I thought the whole point was simplification! And, you’d be right to feel that way. But think of it like this: the stores aren’t competing with each other. They’re specialized. The Lakehouse handles batch engineering and declarative transformations. The Warehouse handles T-SQL serving and procedural logic. The SQL database handles transactional operations. All three sit on the same lake, all three store Delta, and all three can query each other using three-part names.
And then there’s the third shift...
Shift 3: The Warehouse got real developer ergonomics
This one flew under the radar because it wasn’t a single headline announcement. It was a steady accumulation of features across the January-April 2026 updates that collectively made the Warehouse feel like a proper development environment:
The Warehouse now supports explicit user transactions for ALTER TABLE (April 2026). Schema migrations that combine ALTER TABLE with other DDL/DML can be executed atomically in a single transaction. Previously, ALTER TABLE couldn’t participate in explicit transactions, which meant schema changes were risky and non-atomic. That’s fixed now.
Git integration got meaningfully better: branched workspaces give developers clearer visual cues when working with feature branches. Selective branching lets you pick only the items you need for a feature, reducing workspace clutter. And notebook auto-binding means notebooks resolve their Lakehouse references automatically as they move across Git-connected workspaces (dev -> test -> prod).
Cross-database queries work across Warehouses, Lakehouses, SQL databases, and mirrored databases using standard three-part naming. One SELECT can join a dimension from your Warehouse with a fact table in your Lakehouse. No shortcuts needed, no data movement.
And SQL Pool Insights now gives you pool-level telemetry for monitoring and troubleshooting - tracking pressure events, configuration changes, and capacity utilization over time.
The implication: the Warehouse is no longer “just” a query engine. It’s becoming a proper development platform with CI/CD support, transactional DDL, cross-store queries, and observability built in.
So if all three stores are getting more capable and the boundaries are blurring, how do you actually decide?
The decision framework - 4 questions
I don’t use comparison tables in client engagements anymore. There are 50 of those on the internet already, and they all say the same thing. Instead, I ask four questions. The answers tell me which combination fits.
