
Logical Data Management - Storage Was Always the Easy Part
What the warehouse, the lake, and the lakehouse each solve, and what they all leave behind.


Logical Data Management series
Logical Data Management - Storage Was Always the Easy Part (this article)
Logical Data Management: Why “Just a quick number” is never quick...
In the first article of this series, I made a claim that I want to pick apart now: that we spent twenty years getting very good at moving data, and somewhere along the way, the real problem quietly changed shape.
If you missed that one, here is the short version. We solved the movement problem. Data used to be scattered across systems, so we built warehouses, lakes, and lakehouses to bring it together. And it worked. But once everything was in one place, a new problem appeared that storage alone could not fix: the meaning of the data was still scattered, this time across people’s heads instead of across systems.
Fair enough. But that is a big claim to drop and then walk away from. So in this article, I want to do something harder and more honest. I want to look at the three dominant architectures, the warehouse, the lake, and the lakehouse, and ask a specific question about each one.
Not “is it good?” Of course, they are good. Millions of organizations run on them every day.
The question is narrower: what does each one solve really well, and what does it leave on the table?
Because, before we proceed, let me share the key thing: None of these architectures is broken. They are excellent answers. The problem is that some of the questions we are asking in 2026 are not the questions they were designed to answer.
The data warehouse: order at the cost of flexibility
Let us start with the oldest of the three.
The data warehouse was built around a simple, powerful idea: if you define the structure of your data up front, everything downstream becomes easier. Schema-on-write. You decide what the data looks like before it lands, you enforce that structure rigorously, and in return, you get consistency, performance, and trust.
And it delivers on that promise. A well-designed warehouse is a thing of beauty. Queries are fast, the data is clean (well, at least, it should be), and relationships are enforced. When the finance team pulls a report, the numbers tie out because the structure guarantees they tie out. Decades of accumulated engineering, from star schemas to columnar storage to query optimizers, have made the warehouse extraordinarily good at what it does.
So what does it leave on the table?
Flexibility. The same rigid structure that makes the warehouse trustworthy also makes it slow to change. Every new data source needs to be modeled, transformed, and fitted into the existing schema before anyone can use it. Want to bring in semi-structured data, like JSON event logs or sensor readings? You will spend significant effort flattening and structuring it first. Want to explore data before you know what questions you will ask? The warehouse is not built for that. It rewards knowing the questions in advance.
For decades, this was an acceptable trade. Most analytical questions were known in advance, and most data was structured anyway. But the shape of data changed. More of it became messy, nested, high-volume, and fast-moving. And the warehouse, for all its strengths, started to feel like a beautifully organized library that only accepts books in one specific format.
The data lake: flexibility at the cost of order
So the industry swung the other way.
If the warehouse was too rigid, the data lake offered the opposite: store everything, in any format, and figure out the structure later. Schema-on-read. Dump the raw data into cheap object storage, structured or not, and impose meaning at the moment you query it rather than the moment you store it.
This solved real problems. Suddenly you could store data that did not fit neatly into tables, like images, logs, clickstreams, audio, nested JSON. Storage was cheap, so you could keep everything, even data you were not sure you needed yet. Data scientists loved it, because they could access raw data in its original form rather than a pre-modeled version that had already had decisions baked into it.
The lake gave us flexibility and scale that the warehouse could not match.
And then the bill came due.
The same freedom that made lakes powerful also made them dangerous. When you can store anything in any format with no enforced structure, you very often end up storing everything in every format with no enforced structure. The industry even coined a term for what lakes frequently became: data swamps. Lakes full of data that nobody could find, nobody could trust, and nobody quite remembered the meaning of.
Schema-on-read sounds liberating until you are the fifth analyst trying to read the same poorly documented file, each of you interpreting it slightly differently, each of you producing a slightly different number. The structure did not go away. It just moved from the storage layer into the head of whoever happened to be querying the data that day.
Sound familiar? It should. This is the “meaning in too many heads” problem in its purest form.
The lakehouse: can we have both?
By now, you can probably see the pattern, and you can probably guess what came next.
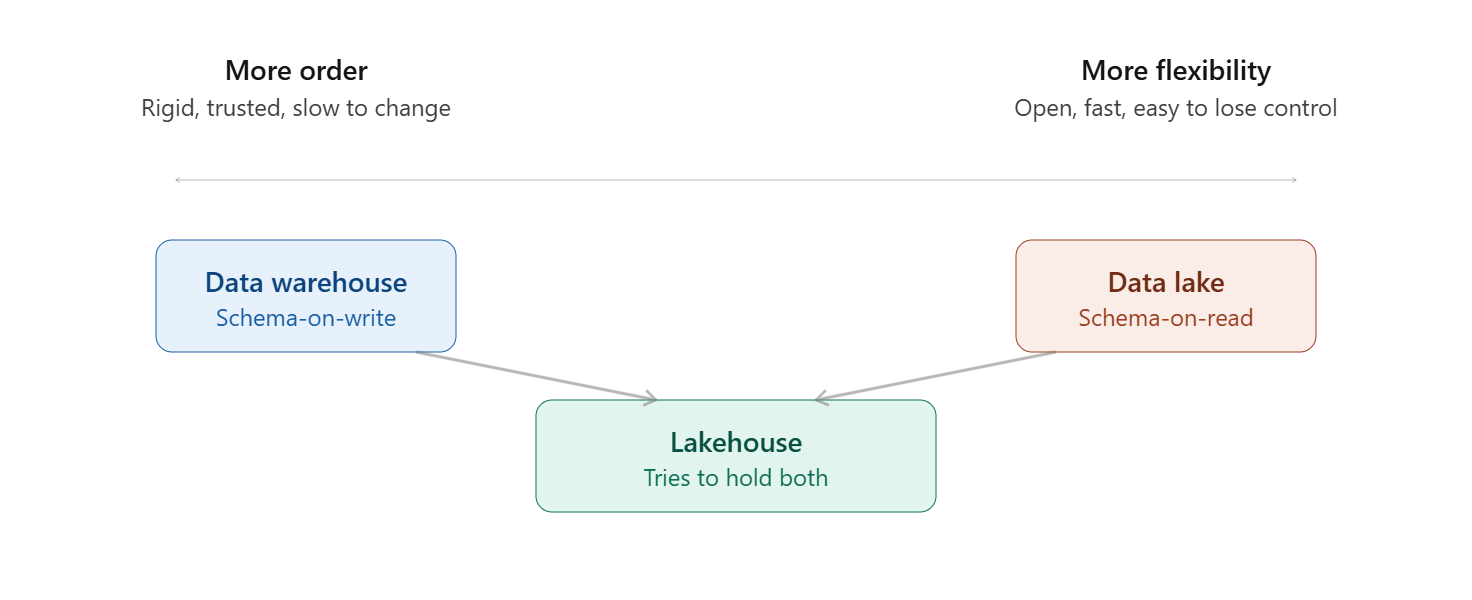
The warehouse gave us order without flexibility. The lake gave us flexibility without order. So the obvious question became: why not both?
That is the lakehouse. The pitch is genuinely compelling: keep your data in cheap, open storage like a lake, but add a transactional metadata layer on top that brings warehouse-like structure, reliability, and performance. Technologies like Delta Lake, Apache Iceberg, and Apache Hudi made this real. You get ACID transactions on top of object storage. You get schema enforcement when you want it and schema flexibility when you do not. You get one copy of the data that can serve both the data scientist exploring raw files and the analyst running a governed report.
I want to be clear: this is a real architectural achievement. The lakehouse is not marketing fluff. The convergence of lake economics with warehouse reliability practically resolved a tension that had forced organizations to maintain two separate systems and copy data between them. Microsoft Fabric, Databricks, Snowflake, and others have built serious, capable platforms on this foundation.
So, with the lakehouse solving the order-versus-flexibility tension, are we done? Did the lakehouse finally answer the question?
It answered a question. A big one. But not the one this series is about.
Here is what the lakehouse still does not give you. It is, fundamentally, still a place where data lives. A very good place, with excellent properties. But the lakehouse is an answer to “where should the data be and how should it be stored?” It manages tables, files, transactions, and schemas brilliantly. What it does not manage, because it was never designed to, is meaning.
A lakehouse will happily store seventeen tables that each contain a column called revenue. It will enforce the schema of each one flawlessly. It will give you ACID guarantees on every write. And it will tell you absolutely nothing about which of those seventeen revenue columns finance actually trusts, what business rules sit behind each one, who owns the definition, or whether “revenue” in this table includes canceled orders.
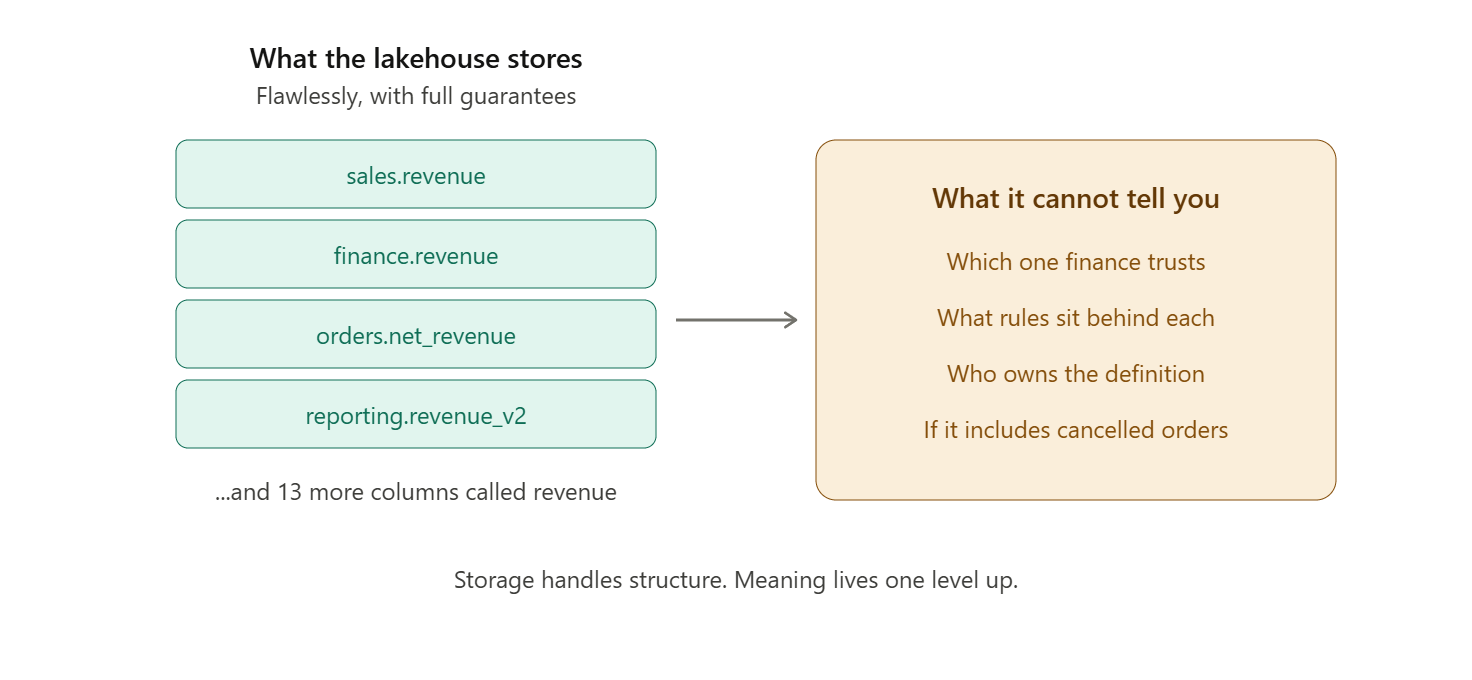
That is not a criticism of the lakehouse. It is a statement about what layer the lakehouse operates at. You would not criticize a warehouse for not making coffee.
The common thread
Now, I want you to take a step back and look at all three together, and something becomes clear.
The warehouse, the lake, and the lakehouse are all answers to questions about storage and structure. Where does the data live? How is it formatted? How do we query it efficiently? How do we keep it consistent? These are important questions, and the progression from warehouse to lake to lakehouse represents real, genuine progress in answering them.
But none of these three architectures was designed to answer a different category of question entirely:
What does this data mean? Which definition is the trusted one? What business rules turn a raw column into a metric someone can make a decision on? Who owns that meaning? How do we make sure a human analyst and an AI agent both interpret “active customer” the same way?
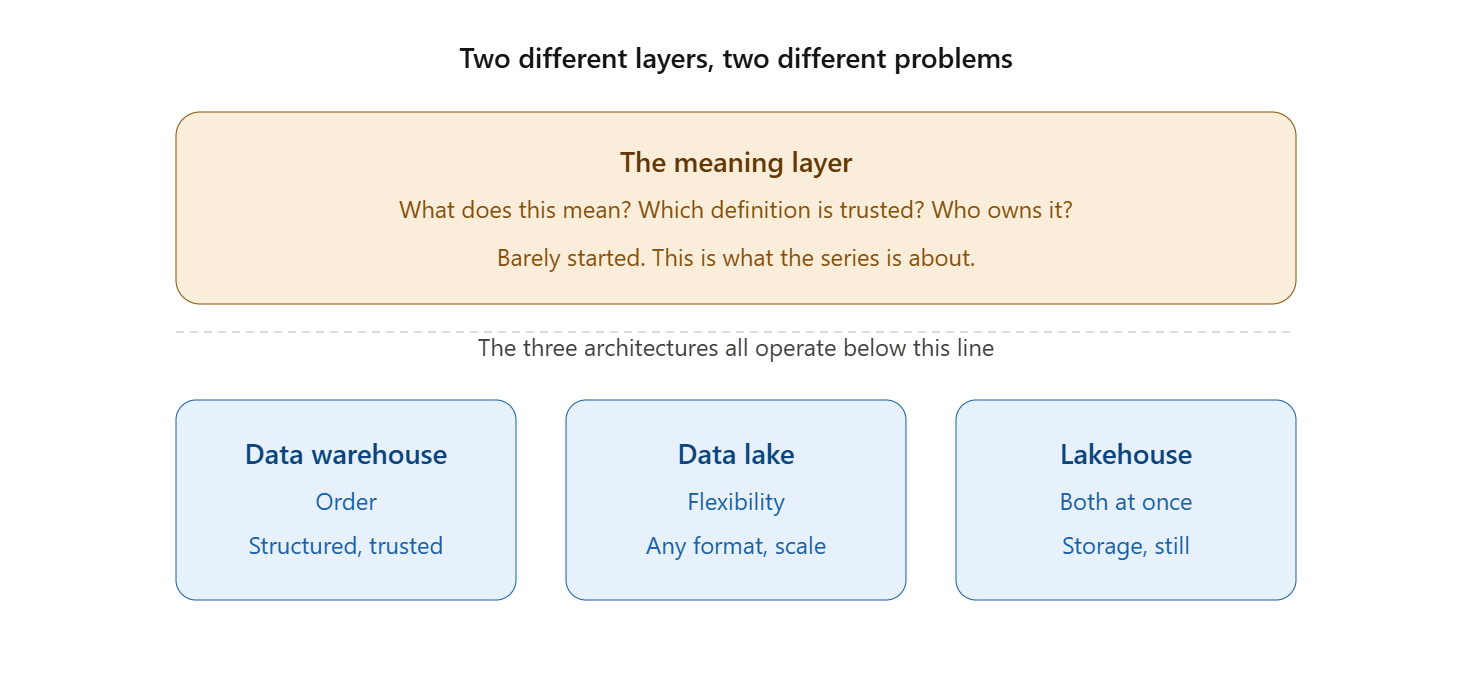
These are not storage questions. They are not solved by a better file format, a smarter query engine, or a more elegant transactional metadata layer. They live one level up, in a layer that sits between where the data is stored and how people and systems actually consume it.
And that, finally, is the gap this series is really about.
I am not going to pretend that logical data management makes warehouses, lakes, or lakehouses obsolete. That would be both wrong and a little insulting to the genuinely brilliant engineering behind all three. You will still need a place to store your data, and a lakehouse may well be the best place yet invented to do it.
The point is narrower, and I think more interesting: the storage problem and the meaning problem are different problems. We have spent twenty years getting very, very good at the first one. We have barely started on the second.
In the next article, I want to leave architecture diagrams behind for a bit and spend a day in the life of the people who feel this gap most acutely: the data users. The analysts, the business users, the people who were promised self-service and got self-navigation instead. Because the limitations I described here are abstract until you watch someone actually run into them on a Tuesday afternoon.
Thanks for reading!
Thanks to Claude for creating these nice-looking diagrams.