
Logical Data Management - One Definition to Rule Them All!
Eleven datasets called revenue, or one definition that everyone shares. The semantic layer is the difference!

Logical Data Management series
Logical Data Management: Why “Just a quick number” is never quick...
Logical Data Management: One Definition to Rule Them All! (this article)
Let me take you back to Sara’s Tuesday for a second.
If you read the previous article, you remember how it went. A simple request for “revenue by region” that should have taken twenty minutes, and instead ate the entire day, not because the data was missing (it was all there, sitting in the lakehouse exactly as designed), but because the meaning was missing. Eleven datasets called revenue. Two definitions that disagreed by eight percent. A forty-line measure with a comment that said “talk to Mike”, and Mike, of course, left the company back in 2023.
Now let me show you a different version of that same Tuesday.
Sara gets the same message at 9:14. Opens the same tool and types “revenue by region”. And this time, there is exactly ONE thing called Revenue - clearly defined (order-based, canceled orders excluded), owned by the finance team, certified three weeks ago. Region is defined once, the same way every single report in the company uses it. Sara drags the two onto the canvas, gets the number, writes a short note, and hits send before the coffee gets cold.
Same data. Same tools. Same Sara. The only difference is that something now sits between Sara and the raw tables and tells her, with authority, what things actually mean.
That something is the semantic layer. And if you take away only one idea from this entire series, please, let it be this one.
Ok, so what the heck is a semantic layer?
Let me give you the plain definition first, and then we’ll take it apart together.
A semantic layer is an abstraction that sits between your physical data and the people (or agents:)) consuming it, translating technical structures into business meaning.
I know, I know - that sentence is dense. So, to put it in plain English: on one side, you have the world of storage. Tables, columns, joins, foreign keys, partitions. A column called rev_amt in a table called fct_ord_ln, joined to dim_geo on a key named geo_sk. Lovely stuff, if you happen to be a database. On the other side, you have actual human beings, who think in words like revenue, region, customer, margin, and quarter, and who have absolutely no idea what fct_ord_ln is, nor should they ever have to.
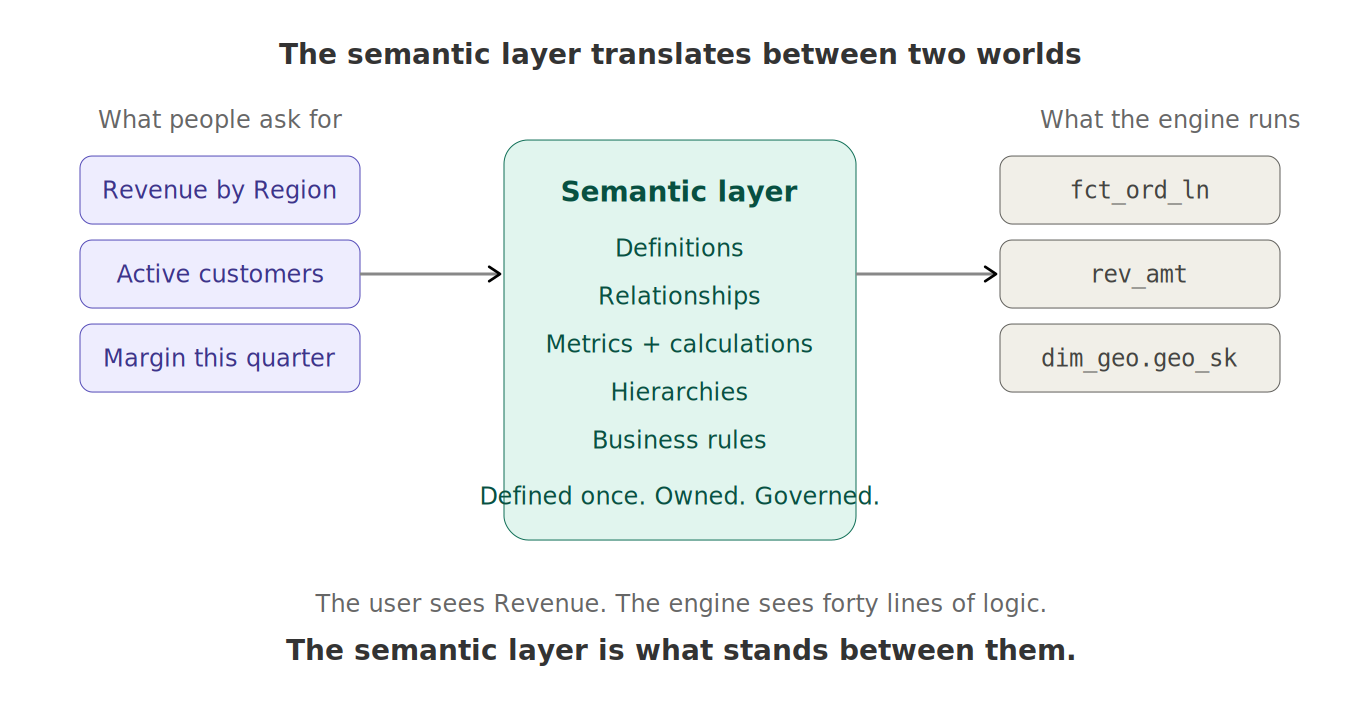
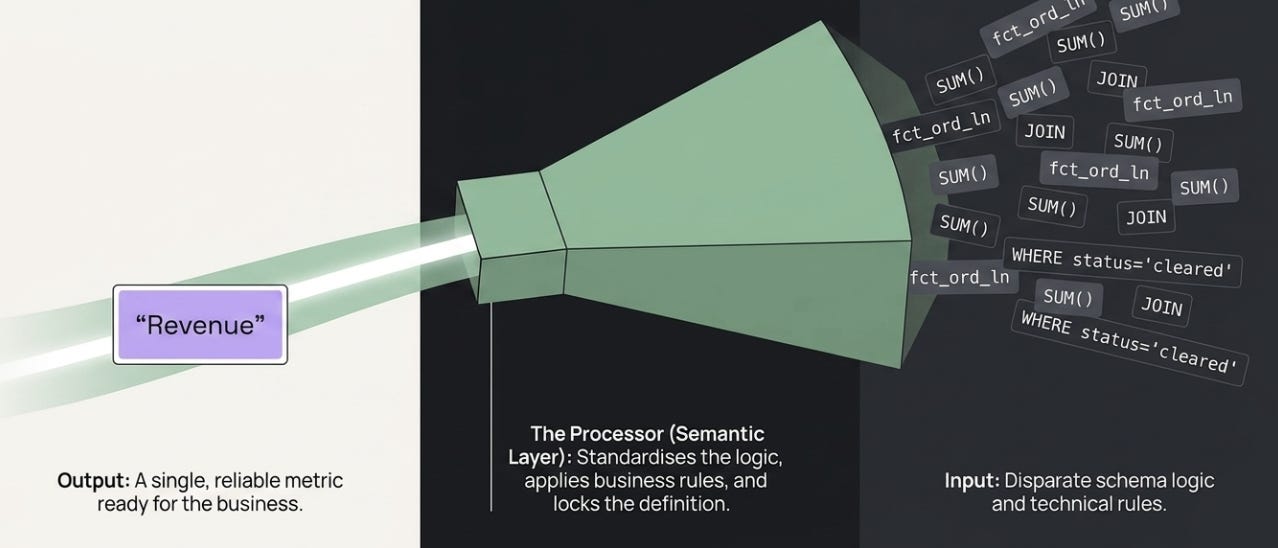
The semantic layer is the translator standing between those two worlds. When someone asks for “Revenue by Region”, the semantic layer is the thing that knows which table to hit, which column to grab, how to aggregate it, how to join to geography, and which business rule takes care of stripping out the canceled orders. The consumer asks for a business concept. The semantic layer turns it into the correct physical query.
The user sees Revenue. The engine sees forty lines of logic. The semantic layer is what stands between them.
Ok, that’s nice, but it’s just pretty naming, right?
This is exactly where most people undersell the whole thing, so let me push back on it directly, because I used to think the same.
It would be easy to read all of the above and conclude that a semantic layer is basically a friendly naming layer, something like a way to rename ugly columns into pretty ones. Useful? For sure. But, hardly the most important thing in your platform.
That undersells it badly. Renaming is just the surface. What the semantic layer really does, and. honestly, this is the part that took me incredibly long to fully appreciate, is give meaning a single home.
Going back to Sara and those eleven datasets... why were there eleven in the first place? Because every team that needed revenue built their own version, in their own report, with their own slightly different logic, for the simple reason that there was nowhere central to define it once. The meaning got duplicated because it was homeless.
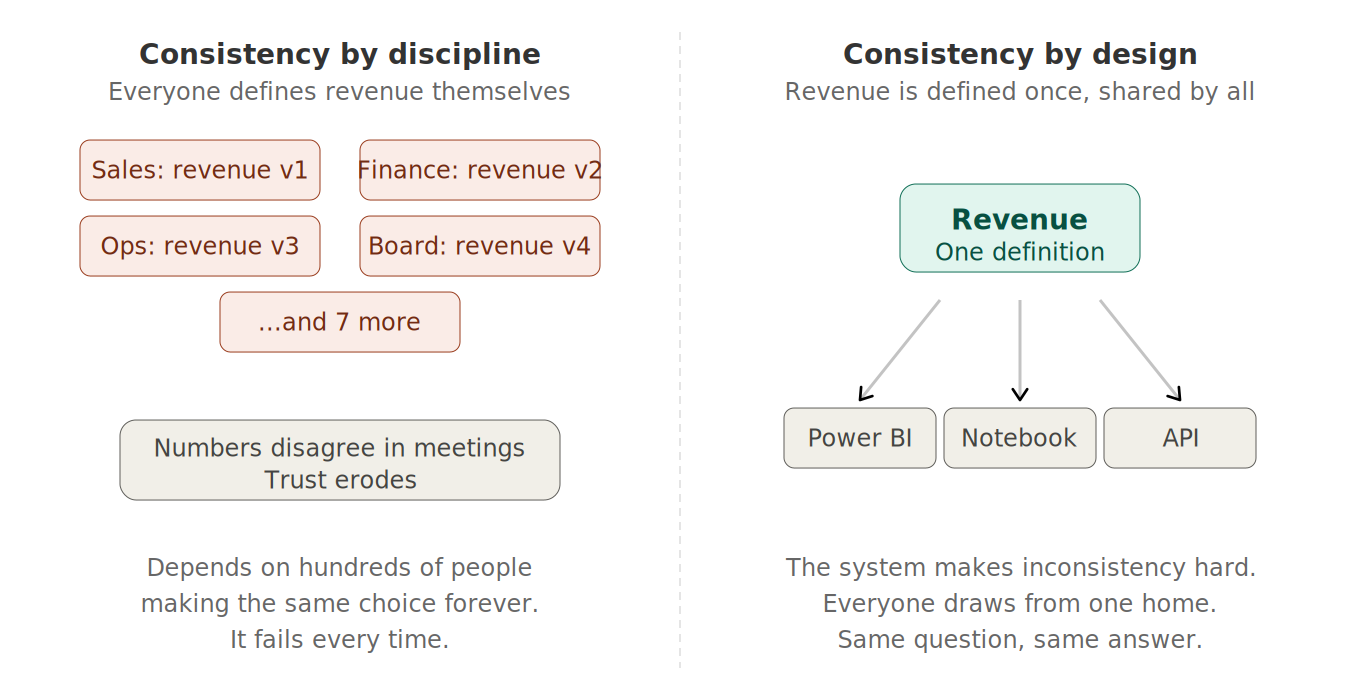
A semantic layer gives meaning a home. Revenue, defined once. Region, defined once. The fiscal calendar, the customer hierarchy, the canceled-orders rule… All defined once, in one place, owned by someone, versioned, documented. And every report, every dashboard, every query that asks for revenue gets the SAME revenue. Not because everybody nobly remembered to use identical logic, but because there is only one logic to use.
This is the whole difference between consistency by discipline and consistency by design. Consistency by discipline is what most of us have lived with: “please, everyone, remember to define revenue the same way.” Keep in mind, this approach fails every single time, because it depends on hundreds of people independently making the same choice, forever, without slipping even once. Consistency by design means the system itself makes inconsistency hard, because the definition lives in one governed place, and everything else just draws from it.
A semantic layer holds way more than names!
So what, concretely, does a semantic layer actually hold? Worth being specific here, because “meaning” is a slippery word, and I don’t want to leave it floating.
A mature semantic layer captures a few distinct things. It holds definitions: what is revenue, what is an active customer, what counts as churn. It holds relationships: how customers connect to orders, orders to products, everything to time. It holds calculations and metrics: not just stored columns, but the derived stuff, like year-over-year growth or rolling averages or margin percentages, the math that turns raw numbers into the figures people actually ask for. It holds hierarchies: how region rolls up to country to continent, how day rolls up to month to quarter to year. And it holds business rules: canceled orders don’t count, internal transfers are excluded, revenue is recognized on shipment for finance but on order for sales.
And then there’s one more thing it holds, increasingly: context for machines. Descriptions, synonyms, constraints - the kind of thing that lets a query engine or an AI agent understand not only the shape of your data but what it actually means and how it’s allowed to be used.
But, more on that later... that thread deserves an entire article of its own, and it’s coming. For now, just tuck it in the back of your mind, because it’s going to end up mattering more than anything else on this list.
Buy it, or build it? Wait - wrong question!
If there is one single question that trips people up, this is the one: Is the semantic layer a product you buy, or a place in your architecture?
The honest answer is that it’s a place, and several very different kinds of products can move into it.
For years, the semantic layer was basically trapped inside the BI tool. Your revenue and region lived inside Power BI, or inside a cube (hello to those of you with a few gray hairs, or no hair, like me), or inside one specific reporting tool. That worked, with one big catch - the meaning was only available to that tool. Want the same revenue definition in a notebook? An API? A different BI tool? Redefine it. The meaning was real, but it was locked in a box.
The big shift in modern data platforms is the move to set the semantic layer free from any single consumer. Meaning shouldn’t belong to Power BI, or to one application. It should sit in a shared layer that anyone can draw from - a Power BI report, a Python notebook, a SQL client, an external app - all asking the same layer for “revenue”, all getting back the same answer. You’ll hear this called a universal semantic layer, or “headless BI” (because the definitions get separated from the visualization “head” that displays them). The labels keep shifting, but the principle doesn’t: define meaning once, in a neutral place, and let every consumer share it. Kurt Buhler (Tabular Editor) has written some of the clearest material out there on semantic models and what they really are. It’s well worth your time if you want to go deeper than the scope of this article allows. And if you want the platform-by-platform view of how this decoupling plays out - how Microsoft, Databricks, Tableau, and others each implement the layer differently - Ruben Van de Voorde's "What is a semantic layer?" is the clearest map I have seen.
I won’t pretend the industry has fully arrived. We’re mid-transition, where some semantic layers are still welded to their BI tool, some are fully independent, and most real organizations run a messy mix of both. But the direction of travel is not subtle. And the reason it matters circles right back to that thread I planted above: the moment the consumers of your data stop being only humans-with-dashboards and start including AI agents, the question of whether your meaning lives in a shared, governed, queryable layer stops being a nice-to-have and becomes the single thing that decides whether those agents can be trusted at all.
Why I’ll die on this hill
I said at the very top that the semantic layer is the most important component in a modern data platform. That’s a big claim, and I’d rather defend it properly than just wave it around.
So let’s run a quick thought experiment. What happens when each layer of your platform is mediocre?
If your storage layer is mediocre, you’ve got a performance and cost problem. Painful, but fixable. Throw hardware at it, tune the queries, restructure the tables.
If your ingestion is mediocre, you’ve got a freshness and reliability problem. Also painful, also fixable, with better pipelines and some monitoring.
But if your semantic layer is mediocre or simply not there, you get a problem that no hardware on earth fixes: NOBODY agrees on what the numbers mean. Two executives walk into the same meeting carrying two different revenue figures. An AI assistant cheerfully reports a metric using the wrong definition. A board slide contradicts the official financials. The data is flawless, the queries are lightning-fast, and the organization still can’t trust a single number it produces.
That, not slow queries, is the failure that actually destroys confidence in a data platform. Disagreement about meaning. And it’s precisely the failure that no storage technology, however brilliant, was ever built to prevent.
This is why I keep banging the same drum across this whole series. We’ve spent twenty years perfecting everything beneath the semantic layer: faster storage, cheaper storage, more flexible storage, unified storage. All real, all good progress. But the one layer that decides whether anyone can trust the output, the layer where meaning actually lives, got treated as an afterthought, bolted onto whichever BI tool happened to be lying around. Logical Data Management is, more than anything else, the argument that this layer has earned the right to be treated as first-class. Designed on purpose, owned by name, governed properly, and shared across every consumer that comes knocking.
Back to Sara, one last time
Sara’s good Tuesday (the imaginary one we opened with) had nothing to do with better data or better tools. Same data. Same tools. The one thing that changed was that meaning finally had a home.
That’s the whole promise of the semantic layer, squeezed into a single analyst’s morning. The data was always there. What was missing was the layer that tells everyone, clearly and with authority, what it all means.
Next time, we get our hands dirty. A single shared layer of meaning sounds wonderful right up until somebody asks how it performs when millions of queries come crashing in, and whether all this lovely abstraction quietly costs you something. The idea is the easy part. Making it fast is the engineering...
Thanks for reading!
Thanks to Claude for creating these nice-looking illustrations.